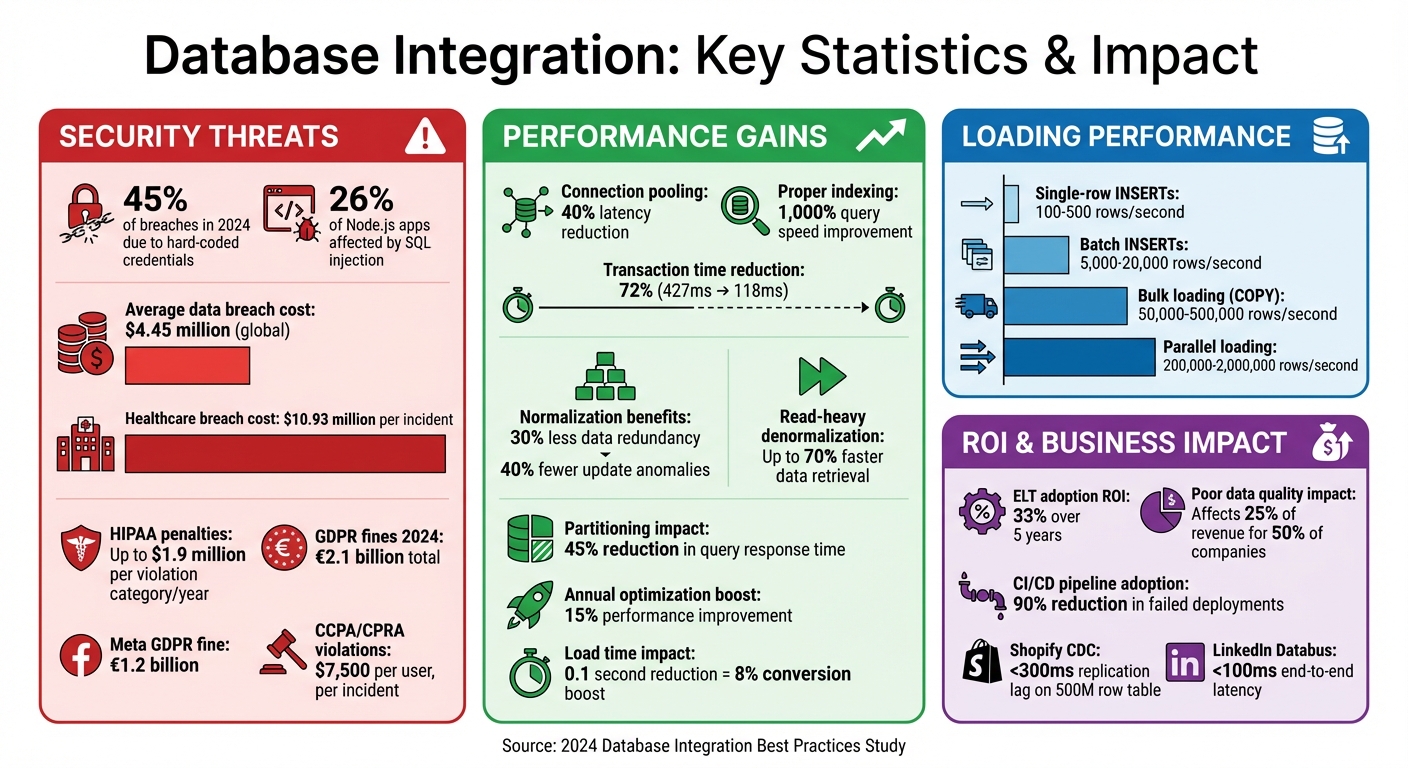
Database integration connects your web app to its backend, ensuring data flows securely and efficiently. But without proper practices, you risk slow performance, security breaches, and scalability issues. For example, in 2024, 45% of breaches were due to hard-coded credentials, and SQL injection affected 26% of Node.js apps. Following these 10 practices can enhance reliability, speed, and security:
- Plan Ahead: Design for scalability, security, and performance (e.g., use connection pooling to cut latency by 40%).
- Use Unique Keys: Ensure data integrity with primary and foreign keys while optimizing indexes for faster queries.
- Choose Efficient Load Types: Opt for batch inserts or CDC (Change Data Capture) to handle large datasets without delays.
- Optimize Performance: Implement normalization, indexing, and connection pools to reduce redundancy and improve query speed.
- Secure APIs: Use parameterized queries, encrypt sensitive data, and prevent SQL injection.
- Document Everything: Maintain clear database schemas, relationships, and data flow documentation.
- Version Control: Treat your schema as code with CI/CD pipelines to avoid errors and ensure consistency.
- Scalability Measures: Plan for growth with horizontal scaling, sharding, or UUID v7 for distributed systems.
- Governance and Access Controls: Enforce row-level security, least privilege access, and regular audits.
- Reconciliation Steps: Validate data through staging tables, error logs, and automated checks.
Key takeaway: Small changes, like shaving off 0.1 seconds in load time, can boost conversions by 8%. These practices ensure your system is secure, fast, and ready for growth.
Database Integration Statistics: Performance, Security & Cost Impact
How to work with any database and do it properly | Ian Barker
sbb-itb-94eacf4
1. Plan Your Data Integration Approach
When planning your database integration, it's important to think ahead about growth, security, and performance. Decisions like picking primary key types may seem small now, but they can become tough to change later on. Early design missteps can turn into costly, complicated challenges as your application scales and your reporting needs grow. To avoid these pitfalls, focus on strategies for optimization, security, and scalability from the start.
Performance Optimization
Start by using normalization techniques (1NF-3NF) to reduce redundancy. Tailor your indexing to fit common query patterns, especially for columns used in WHERE filters, JOIN conditions, and ORDER BY clauses. For example, organizations that prioritize normalization often see a 30% drop in data redundancy and a 40% decrease in update issues.
If your system leans heavily on read operations - say, over 70% - consider selective denormalization or materialized views to speed things up. In read-heavy environments, strategic denormalization can cut data retrieval times by up to 70%.
Connection management also plays a major role in performance. Properly tuned connection pools can reduce transaction times significantly - by as much as 72%, from 427 milliseconds to just 118 milliseconds. Tools like PgBouncer can help manage connections efficiently, especially during traffic spikes. Additionally, using optimistic concurrency control with version columns can help minimize locking issues in high-traffic applications.
Security and Compliance
Security isn’t something to bolt on later - it needs to be part of your design from the beginning. This is especially critical if you need to comply with regulations like GDPR or HIPAA. For SaaS platforms, consider adding a tenant_id to all tables and implementing Row-Level Security (RLS) to prevent data leaks between tenants.
Audit logs are another must. Use audit columns like created_at, updated_at, created_by, and updated_by, or set up dedicated audit tables. Apply the Principle of Least Privilege by defining specific roles like readonly or data_analyst to restrict access. For privacy and compliance, use soft deletes with an is_deleted flag instead of hard deletes. This approach preserves historical data and aligns with privacy laws.
Scalability and Flexibility
To handle future growth, design your system to stay flexible under increased load. Map out your expected user growth for the next 24 months to determine whether you’ll need horizontal scaling or sharding. For instance, e-commerce platforms often face traffic spikes of 2× to 5× during seasonal sales, so planning for these surges is crucial.
If you're building for distributed or multi-tenant environments, use scalable identifiers like UUID v7 to avoid collisions down the line. Choose your data store wisely: relational databases for transactions, document or key-value stores for flexible schemas, and columnar databases for analytics.
Plan for horizontal growth early by incorporating partitioning (within a single node) or sharding (across multiple machines) before your tables grow too large. Retrofitting these features into a live system is risky and should be avoided whenever possible.
2. Use Unique Keys Correctly
Getting unique keys right is a cornerstone of building a reliable database. Primary keys serve as the unique identifier for each row, ensuring no duplicates creep into your data. This makes it possible to reference entities like customers, orders, or products consistently throughout your system. Meanwhile, foreign keys connect records across tables, preserving relationships and preventing "orphan records" - cases where a record refers to non-existent parent data.
"Intelligent key design directly impacts database normalization and analytics, making or breaking system reliability." - Marcus Newman, Database Designer
Data Integrity and Accuracy
Keys play a critical role in maintaining data quality. Primary keys enforce uniqueness and require non-null values, while foreign keys ensure table relationships remain valid. For instance, if a customer record is deleted, foreign key constraints can either block the deletion (RESTRICT) or automatically delete related records like orders (CASCADE), depending on how they're set up.
"Foreign keys prevent this [orphan records] by forcing valid relationships between tables. The database becomes the guardrail, not just your application code." - Refact
Beyond primary and foreign keys, applying UNIQUE constraints to business identifiers like email addresses helps eliminate logical duplicates. This approach allows you to use a surrogate primary key while ensuring consistency in your data.
Performance Optimization
Unique indexes aren't just about enforcing rules - they also speed up queries. By using a unique index, the database can stop searching as soon as it finds a match, saving resources. In one SQL Server test, queries with unique indexes used about one-third of the resources compared to non-unique indexes, with CPU time dropping from 1,186 ms to just 266 ms for the same dataset.
"SQL is generally pretty happy to get good information about the data it's holding onto for you. If you know something will be unique, let it know. It will make better plan choices." - Erik Darling, SQL Server Expert
Keeping primary keys compact is another way to boost performance. For example, using BIGINT instead of TEXT reduces storage needs and improves indexing efficiency. Since the size of a primary key affects every index and foreign key referencing it, smaller keys lead to faster database operations. Additionally, always index foreign key columns to avoid full table scans during JOIN operations.
Scalability and Flexibility
Surrogate keys, like auto-increment integers or UUIDs, are a better choice than natural keys (e.g., email addresses or product SKUs) for most scenarios. Surrogate keys remain stable even when business rules evolve, shielding your application from schema changes. While 32-bit integers (INT) can handle up to 2.1 billion rows, switching to BIGINT for high-growth tables ensures you won't hit a row limit unexpectedly.
For distributed systems, microservices, or multi-tenant applications, UUID v7 offers a smart alternative. Unlike random UUIDs, UUID v7 is time-ordered, which improves index sorting and avoids the write hotspots that sequential integers can create in distributed databases like CockroachDB. This time-ordering also helps prevent ID collisions when merging data from multiple sources.
| Key Type | Best Use Case | Performance Impact |
|---|---|---|
| Auto-increment (BIGINT) | Single-node, high-volume rows | Compact and fast but creates hotspots in distributed systems |
| UUID v7 | Distributed systems, multi-tenant SaaS | Prevents hotspots; time-ordered for better index performance |
| Natural Key | Small, static reference tables | Can cause performance issues if business data changes |
Security and Compliance
For public-facing APIs, UUIDs add an extra layer of protection by making ID enumeration attacks much harder. Sequential IDs can be guessed, but UUIDs are far more difficult to predict. In multi-tenant SaaS systems, including tenant_id in unique keys and indexes ensures strict data isolation, reducing the risk of cross-customer data leaks. This approach not only protects sensitive data but also helps meet compliance standards like GDPR and HIPAA.
3. Choose Your Load Types Early
Getting data into your database efficiently is a cornerstone of integrating databases with advanced web building tools. Deciding on your data loading method early can make a big difference in terms of performance, security, and accuracy.
Performance Optimization
Not all loading methods are created equal when it comes to speed. For example, single-row INSERTs handle only 100–500 rows per second because each row requires its own network trip and transaction. On the other hand, batch INSERTs group records together, significantly increasing throughput to 5,000–20,000 rows per second. But if you're working with millions of rows, native bulk loading commands like PostgreSQL's COPY or MySQL's LOAD DATA INFILE are the way to go - they bypass the SQL parser and can process anywhere from 50,000 to 500,000 rows per second. For even higher performance, parallel loading splits the data across multiple workers, achieving speeds of 200,000–2,000,000 rows per second.
"Bulk loading is the difference between waiting hours for data ingestion and finishing in minutes. When you are moving millions of rows, every optimization matters." - nawazdhandala, OneUptime
To make bulk loading even faster, drop non-essential indexes and foreign keys beforehand - this can reduce write times by 10–30%. Setting tables to UNLOGGED can double throughput as well. After loading, always run ANALYZE to refresh query optimizer statistics. Without this step, stale data distribution info could lead to sluggish query performance.
While speed is important, your choice of loading strategy also impacts scalability and how you manage data in the long run.
Scalability and Flexibility
Deciding between ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) early can save you from future headaches. In cloud environments, ELT is often the better choice because it loads raw data quickly and uses native compute engines for transformations, making it more scalable. ELT also keeps raw data intact, which is helpful for audits, reprocessing, or reproducing results without needing to access the original source systems again.
However, if you're working in a regulated industry - say, handling PII or HIPAA-compliant data - ETL becomes essential. Sensitive information needs to be masked or validated before it lands in your central storage. Additionally, define your latency needs (batch vs. streaming) early to avoid building overly complex pipelines that don't align with your actual requirements.
Once you've nailed down performance and scalability, it's time to focus on ensuring your data is accurate and error-free.
Data Integrity and Accuracy
Staging tables are a great way to validate data before it enters production. Think of them as a safety net where you can check data types, ranges, and business rules - like ensuring quantities are positive or status codes are valid - so you can catch problems early. If you've disabled foreign keys to speed up bulk loads, you'll need a reconciliation step afterward to confirm that referential integrity hasn't been compromised.
Classify errors into two categories: retryable issues (like network timeouts) and data errors (like constraint violations). This helps you avoid wasting time on endless retries. To prevent duplicate records, use unique constraints and idempotency keys. These measures ensure your data remains clean and reliable, even in large-scale operations.
4. Use Incremental Loading with Change Data Capture (CDC)
Building on the choice of efficient load types, using incremental loading through Change Data Capture (CDC) can help conserve resources. CDC focuses on recording only new, updated, or deleted rows, avoiding the need for expensive full table scans.
Performance Optimization
Log-based CDC is often seen as the best choice for handling high data volumes. It works by reading database transaction logs - like PostgreSQL's WAL or MySQL's binlog - without disrupting application queries. This approach minimizes CPU usage and I/O load on production databases. By transmitting only the row-level changes, CDC significantly reduces network and processing demands. Switching from batch updates to log-based CDC can cut data lag from hours down to mere seconds.
"Log-based CDC is generally the best option for [high-volume] environments, as it reads directly from database transaction logs (WAL) and minimizes the impact on production workloads."
- Khalid Abdelaty, Data Engineer, DataCamp
Unlike polling methods, which only capture the final state of changes, CDC records every change event. This means it preserves intermediate states and provides a full audit trail, which is essential for industries like finance or healthcare that require strict compliance. However, in write-heavy environments, trigger-based CDC may double I/O because every write to the source table results in an additional write to a change table.
Scalability and Flexibility
CDC is a natural fit for event-driven systems, allowing web applications, search indexes, and analytics tools to subscribe to a real-time stream of database updates without relying on constant polling. For instance, Shopify uses Debezium for log-based CDC across more than 200 production tables, including an orders table with 500 million rows. Despite the scale, they maintain replication lag below 300 milliseconds. Similarly, LinkedIn's Databus framework handles millions of events per second with end-to-end latency under 100 milliseconds. By decoupling the source database from downstream systems, CDC scales horizontally and avoids bottlenecks. These capabilities align well with other best practices for maintaining system reliability.
Data Integrity and Accuracy
To ensure updates and deletes are applied correctly, every table using CDC must have a primary key or unique index . Using a Log Sequence Number (LSN) as an idempotency key helps prevent duplicate events during replays. Monitoring replication lag is also critical - Stripe, for example, sets alerts if replication slot lag exceeds 30 minutes to avoid transaction log bloat and potential database crashes. Additionally, dead letter queues (DLQ) can capture "poison messages" that fail repeatedly, preventing them from blocking the entire data pipeline. This meticulous approach to CDC ensures both reliable performance and accurate updates across systems.
"CDC is what makes 'near real time' actually reliable, because you are capturing committed changes at the source."
- Jonas Thordal, Co-founder, Weld
5. Write Clear Interface Documentation
Once you've established CDC and integration patterns, the next step is to document every interface clearly. Think of this as creating a blueprint for your entire database integration. This documentation ensures that developers, DBAs, and future team members understand how data flows, the reasoning behind design decisions, and how to keep the system accurate as it evolves. It becomes the cornerstone for maintaining data integrity, supporting growth, and ensuring compliance.
Data Integrity and Accuracy
Your documentation should get into the nitty-gritty of how data is structured and maintained. For example, include details about foreign key relationships and their deletion rules (like CASCADE or RESTRICT) to avoid orphaned records. Specify why certain data types were chosen, such as using DECIMAL for financial data or TIMESTAMP WITH TIME ZONE for precise time management.
It’s also important to outline audit trail patterns that track changes - who made them, what was changed, and when. Additionally, describe soft delete logic, such as using is_deleted flags, to preserve historical data while keeping the system tidy.
"Document every decision in your engineering notes to ensure team-wide clarity." - Refact
By applying rigorous normalization practices, organizations have reported a 30% drop in data redundancy and a 40% decrease in update anomalies.
Scalability and Flexibility
Good documentation does more than just explain - it prevents knowledge from being stuck in one person’s head. Record every architectural decision, such as whether you opted for UUIDs or sequential bigint primary keys, and explain why. If you’ve denormalized for performance, make sure you document the exact method - whether it’s triggers, background jobs, or application logic - used to keep that data synchronized.
Treat your database schemas like versioned code. Document changes incrementally through your CI/CD pipeline, which allows for ongoing improvements rather than trying to build the "perfect" model upfront. For multi-tenant SaaS products, clearly outline how you’re isolating tenant data, such as with tenant_id columns, to prevent accidental data leaks as the system scales.
Security and Compliance
A centralized data dictionary is a must. This should define every table and column, covering data types, constraints, default values, and plain-language descriptions of their purpose. Document roles like readonly or data_analyst, and specify the least privilege permissions required for each interface to operate securely.
Include Row-Level Security (RLS) and column-level encryption details so that developers understand how sensitive data is being protected at the database layer. To keep everything consistent, version-control your interface documentation alongside your application code.
"An undocumented database is a ticking time bomb for any development team." - Cody Yurk, Web Developer
6. Add Reconciliation and Verification Steps
Once your interfaces are documented, the next move is incorporating reconciliation and verification steps into your integration workflow. These steps act as your safety net, catching potential issues like data corruption, failed migrations, or broken constraints before they cause problems in production. Reconciliation involves comparing data from various sources to confirm accuracy, consistency, and completeness, while verification ensures your database structure and rules are functioning as intended. Together, these steps strengthen the reliability of your data integration process.
Data Integrity and Accuracy
A solid reconciliation process typically includes several stages: extraction, standardization, matching, identifying discrepancies, resolving issues, and logging the final audit. For matching, you can use different techniques depending on your needs:
- Deterministic matching for exact field matches (e.g., invoice numbers).
- Probabilistic matching to calculate the likelihood of a match based on multiple factors.
- Fuzzy matching to handle small inconsistencies, like "McDonald's" versus "McDonalds".
Reconciliation should happen at multiple levels. Transaction-level reconciliation focuses on individual records for detailed accuracy, while balance-level reconciliation checks high-level summaries. Before diving into reconciliation, run pre-checks to ensure completeness and proper formatting, which can save time and resources.
"Transaction reconciliation - the process of comparing internal financial records against external statements to verify accuracy - sits at the heart of every reliable close." - Nigel Sapp, Numeric
Performance Optimization
Reconciliation can be resource-intensive, so efficiency is crucial. Use connection pooling to minimize connection overhead. Instead of reconciling entire datasets, focus on segmented data and only reconcile records that have changed. Speed up lookups by adding indexing to frequently used columns in WHERE clauses and JOIN conditions. For large datasets, limit the scope to key attributes rather than comparing every field.
Security and Compliance
To meet regulations like SOX, HIPAA, and SEC, log every discrepancy, resolution, and approval in a detailed audit trail. Assign clear account ownership and set up standardized approval workflows for adjustments to maintain separation of duties. At the API and model levels, validate and sanitize inputs to block SQL and NoSQL injection attempts.
Scalability and Flexibility
Manual reconciliation isn’t practical for growing datasets. Automation can handle most matching tasks, allowing the process to scale without requiring more staff. Reserve human resources for high-risk accounts that could significantly impact financial statements or operations. Define variance thresholds by transaction type - like distinguishing FX-related differences from cash discrepancies - to avoid unnecessary manual reviews. Additionally, separate timing differences (e.g., uncleared checks) from true data issues to reduce noise and streamline your reconciliation process.
7. Apply Version Control and CI/CD
Integrating version control and CI/CD processes into your database workflows takes reliable deployments to the next level. By treating your database schema and migration scripts as code - tracked in Git and deployed through automated pipelines - you eliminate the manual errors often associated with traditional deployments. Version control acts as the single source of truth, ensuring database schema versions align perfectly with corresponding application code versions. This approach prevents "schema drift" and keeps everything in sync. Meanwhile, CI/CD automation consistently tests, validates, and deploys changes across development, staging, and production environments.
Data Integrity and Accuracy
Automated tests within CI/CD pipelines are essential for catching schema issues before they hit production. If a deployment fails, these pipelines can automatically roll back to the last stable state. To make debugging and rollbacks simpler, ensure migration scripts are idempotent and represent just one logical change.
"One migration = one logical change... It simplifies the debug, review, rollback and audit."
- Adela, Bytebase
Performance Optimization
CI/CD pipelines also help identify performance bottlenecks before they become a problem. Tools for static analysis and linting can flag non-performant queries - like those missing primary keys or essential filters - before they reach production. High-performance teams, such as SAP HANA, have integrated performance tests directly into the pre-commit stage of their CI processes. This setup helps them detect anomalies and manage long-running benchmarks with minimal manual effort. Similarly, MongoDB runs fully automated performance tests in their CI environment, which includes provisioning large clusters and collecting data to boost developer productivity.
Performance improvements not only enhance efficiency but also free up DBAs to focus on strategic tasks like performance tuning and system upgrades. By automating tedious SQL reviews, CI/CD pipelines allow teams to standardize deployments and tighten security.
Security and Compliance
Automation plays a critical role in reducing security risks, such as misplaced GRANT statements or misconfigurations introduced during manual deployments. CI/CD pipelines also integrate environment-specific secrets management, ensuring database credentials are never hardcoded into scripts. With version control, you get a complete audit trail, which is crucial for meeting compliance requirements. In fact, a 2024 study showed that adopting CI/CD pipelines for database applications led to a 90% reduction in failed deployments during testing.
Scalability and Flexibility
Combining CI/CD with Infrastructure as Code (IaC) tools like Terraform enables rapid and consistent provisioning of isolated database environments for testing. This setup significantly boosts development scalability. Packaging database code into immutable artifacts ensures consistency across all environments. This method ensures that your database evolves in lockstep with your application code.
"A fast CI/CD pipeline allows developers to fix issues that go into production quickly due to faster turnaround times... improving the company's bottom line via better Mean Time to Recovery (MTTR)."
- Charles Mahler, InfluxData
8. Use Flexible Architectures like ELT
Modern data architectures are increasingly leaning toward ELT (Extract-Load-Transform) for handling data at scale. Unlike traditional ETL, this method loads raw data directly into a warehouse before transforming it using the warehouse’s built-in processing power. This shift has redefined how web applications manage large-scale data.
Scalability and Flexibility
ELT stands out for its ability to scale efficiently, thanks to cloud-native platforms like Snowflake, BigQuery, and Redshift. These platforms use their elastic compute power to handle transformations, eliminating the need for a dedicated transformation server - a common bottleneck in ETL workflows. By leveraging the warehouse's SQL engine, ELT enables "push-down" transformations that can scale seamlessly as data grows.
This method also preserves raw data, allowing teams to create custom pipelines without altering the original dataset. Over five years, businesses have seen a 33% ROI from adopting ELT.
"In most modern stacks, ELT is the standard. It's cheaper to run, easier to scale, and better aligned with tools like dbt that bring software engineering best practices to analytics workflows."
- Daniel Poppy, dbt Labs
The result? Faster and more efficient data processing, even as your data demands grow.
Performance Optimization
One of ELT’s key advantages is speed. Since data is loaded before transformation, ingestion times are significantly reduced. Cloud warehouses excel at set-based operations, outperforming the row-by-row processing typical of ETL. Features like effective partitioning can reduce query response times by 45%.
For high-traffic web applications, materialized views can pre-aggregate data, making dashboards load faster by cutting read latency. Additionally, ELT-specific indexing strategies can dramatically improve query speeds. To save both time and resources, focus on incremental loads - processing only new or updated records instead of refreshing the entire dataset.
These performance improvements make ELT a natural fit for modern data workflows.
Data Integrity and Accuracy
ELT’s approach to loading raw data creates an immutable audit trail, which is invaluable for error handling and reprocessing. This is critical, especially since 50% of companies report that poor data quality affects at least 25% of their revenue.
Automated testing and version control tools like dbt help catch data quality issues before they impact dashboards. Idempotent pipelines, which produce the same results regardless of how many times they run, further ensure data reliability. Staging tables can also be used to isolate and reprocess errors without disrupting other workflows.
Security and Compliance
While ELT’s retention of raw data supports robust audit trails, it also requires strong governance measures. Implement Role-Based Access Control (RBAC) and PII masking to safeguard sensitive information. Establish clear data contracts between producers and consumers to avoid unexpected issues. Observability tools can track data from its source to final insights, ensuring users can trust both its accuracy and timeliness.
9. Set Up Governance and Access Controls
When it comes to securing your database environment, governance and access controls are essential. They build on earlier security practices to ensure your data remains protected and compliant.
Security and Compliance
Database governance isn't just about safety - it's a financial safeguard. In 2023, the average global cost of a data breach hit $4.45 million, a 15% rise since 2020. Healthcare organizations face even higher stakes, with breaches costing an average of $10.93 million per incident. On top of that, failing to comply with regulations like HIPAA can lead to penalties as steep as $1.9 million per violation category per year.
A solid security framework starts with the Principle of Least Privilege (PoLP), which ensures users and service accounts only get the permissions they absolutely need. This reduces the risk of damage if credentials are compromised. Relying solely on application-layer security isn't enough; if the application server is breached, attackers can bypass logic checks and access the database directly. That's why database-native controls, like Role-Based Access Control (RBAC) and Row-Level Security (RLS), are critical for managing permissions and securing multi-tenant environments.
"If the application server is compromised, an attacker with direct database connectivity bypasses all application logic entirely. Database-native controls... must be independent of application enforcement." - Database Systems Authority
Protecting your data at all stages is equally important. Use TLS 1.2+ to secure data in transit, Transparent Data Encryption (TDE) for data at rest, and column-level encryption for sensitive fields like Social Security numbers or protected health information. While TDE may add 5% to 8% CPU overhead, and column-level encryption might limit index-based lookups, these trade-offs are essential for robust security.
Data Integrity and Accuracy
Good governance also ensures data quality. Conduct quarterly access reviews to revoke outdated permissions and avoid "permission drift". Automate audit trails by using database triggers to populate created_at and updated_at fields with UTC timestamps. Additionally, log all privileged account activity, schema changes, and failed login attempts. Route these logs to a write-once, out-of-band system to maintain forensic integrity.
Treat database changes like code by using migration tools such as Flyway or Liquibase. These tools help keep schemas consistent across environments and provide a clear history of changes. Eliminate unnecessary risks by removing default accounts, sample schemas, and unused features, and ensure your operating system follows secure baselines like the CIS Benchmarks.
These steps not only improve data accuracy but also make managing permissions easier as your organization grows.
Scalability and Flexibility
Scaling access controls efficiently is crucial. Transitioning from Discretionary Access Control (DAC) to RBAC simplifies administration by grouping permissions under roles rather than managing them individually. For multi-tenant SaaS systems, RLS isolates tenant data automatically, removing the need for complicated application-side filtering.
Centralizing identity management with tools like LDAP or SAML federation further streamlines credential administration. This approach eliminates the need for siloed systems, making it easier to manage access across your database portfolio while maintaining strong security standards.
Finally, adopt the 3-2-1 backup rule: keep three copies of your data on two different media types, with one stored off-site. This ensures your data is protected against loss or disaster.
10. Build Secure APIs with Privacy by Design
In today's digital landscape, creating secure APIs is non-negotiable. They serve as the backbone for database connections and user data exchanges, making their protection critical. By designing APIs with Privacy by Design principles, you not only safeguard sensitive information but also maintain user trust. This is especially important in an era where GDPR fines hit €2.1 billion in 2024, with Meta alone facing a staggering €1.2 billion fine for illegal data transfers.
Security and Compliance
A secure API starts with data minimization. Instead of exposing entire database rows, use field whitelisting to control which fields are accessible through the API. This approach reduces the risk of unintentionally leaking sensitive details like password_hash or internal_notes. To further enhance security, rely on Data Transfer Objects (DTOs) to filter sensitive data before sending responses to clients - never send raw database records directly.
For authentication, adopt OAuth 2.0 or OpenID Connect protocols. Pair these with the Backend-for-Frontend (BFF) pattern, which ensures API keys and secrets remain secure and out of client-side applications. Always encrypt data in transit and at rest using industry-standard protocols.
"Build like every request could be an attack - and you'll be ready when one is."
- Maria Paktiti, WorkOS
Privacy regulations also demand specific features. For example, create endpoints that handle Data Subject Access Requests (DSAR) and the Right to Be Forgotten. These endpoints should programmatically delete or anonymize data across databases, backups, logs, and even third-party systems. Under CCPA/CPRA, violations can cost as much as $7,500 per user, per incident. Additionally, implement a consent management system that logs when and how users accepted your privacy policy, including the version they agreed to, and allows them to withdraw consent easily.
Performance Optimization
Security doesn’t have to come at the cost of speed. For example, use idempotency keys to prevent duplicate database entries or charges when API requests are retried due to network issues. Introduce rate limiting - such as 100 requests per minute per user - to protect against brute-force attacks while maintaining smooth performance for legitimate users. Include headers like X-RateLimit-Limit, X-RateLimit-Remaining, and X-RateLimit-Reset so clients can manage their request rates effectively.
These strategies ensure your APIs remain fast and reliable without compromising security.
Data Integrity and Accuracy
Maintaining data integrity is just as critical as securing it. Use parameterized queries and schema validation libraries to sanitize inputs, preventing SQL injection attacks. Standardize error messages to display generic responses like "Invalid Input" to users while logging detailed diagnostics server-side. This prevents attackers from gaining insights into your infrastructure.
Logging is another key aspect. Track all access to personally identifiable information (PII) with a correlation ID to trace data use across systems, which is essential for compliance audits. From the start, version your APIs using URL paths like /v1/ and /v2/. This allows for breaking changes - like those required by new privacy laws - without disrupting existing integrations.
Finally, keep your secrets safe. Store database credentials and API keys in secure vaults like AWS Secrets Manager or HashiCorp Vault instead of embedding them in your codebase.
"Privacy regulations don't just affect lawyers and compliance officers. Developers make the architectural decisions that determine whether an application is compliant or not."
- SCR Security Research Team
Comparison Table
Choosing the right load type can significantly influence performance, cost, and scalability. Here's a breakdown of the four main loading methods, highlighting their complexity, resource needs, implementation techniques, and ideal use cases for web applications:
| Load Type | Complexity | Resource Requirements | Implementation Method | Best-Use Scenario |
|---|---|---|---|---|
| Full Load | Low | High I/O & Compute | TRUNCATE and reload all data | Best for small datasets or synchronization tasks |
| Delta (Incremental) | Medium | Low (processes only changes) | Uses last_updated timestamps or keys |
Perfect for large datasets needing frequent updates |
| Snapshot (Differential) | High | High (Storage & Compute) | Row-by-row comparison of snapshots | Useful for legacy systems without change tracking or for point-in-time reporting |
| CDC | High | Very High (Setup/Privileges) | Log-based or trigger-based capture | Ideal for real-time streaming and modern data pipelines |
Understanding the Load Types
Full loads are straightforward but can disrupt table availability during reloads. They're optimal for initial migrations or small datasets where it's simpler to overwrite all data rather than track changes.
Delta loads work well for large and dynamic datasets. By focusing only on new or updated records, they reduce resource use and support frequent updates. However, they depend on reliable change-tracking systems like last_updated timestamps, surrogate keys, or audit columns. Interval-based incremental loading can also help identify and fix data gaps.
Snapshot loads require significant storage since they involve maintaining and comparing previous snapshots. This approach is especially helpful for older systems without built-in change tracking or when historical data and point-in-time reports are essential.
CDC (Change Data Capture) stands out for its near real-time capabilities by reading transaction logs, such as PostgreSQL's WAL or MySQL's binlog. While this method is excellent for event-driven systems, it demands more complex setup and elevated database privileges compared to other methods.
Wrapping It All Up
Integrating databases effectively lays the groundwork for better performance, stronger security, and seamless scalability. The strategies we've covered focus on the essentials: planning before coding, using secure APIs with parameterized queries, and selecting architectures that grow with your application rather than holding it back.
The numbers back this up. For instance, connection pooling can reduce latency by as much as 40%, and proper indexing can speed up queries by a staggering 1,000%. On the security side, 45% of data breaches in 2024 were tied to exposed credentials, injection flaws impact 26% of Node.js-based business apps, and the average cost of a data breach now exceeds $4 million.
"Data integration isn't just a technical exercise anymore - it's foundational to a business' ability to move quickly, make informed decisions, and scale sustainably." - Dmitri Tverdomed, Data Architect and Director at Zooss Consulting
To make the most of these practices, start with normalization to maintain data integrity, and only denormalize when performance demands it. Decide on your data load strategy early - whether Delta, Full, or CDC - based on the size and update frequency of your datasets. Treat your database schema as code, using versioned migrations in CI/CD pipelines, and always validate inputs at the route level to block malformed data from reaching your database.
The benefits go far beyond short-term fixes. Companies that prioritize normalization report a 30% drop in data redundancy and a 40% decrease in update anomalies. Meanwhile, ongoing database optimization delivers an average annual performance boost of 15%. By adopting these principles, you’ll not only tackle immediate issues but also build a robust integration framework that supports long-term growth. These practices ensure your system is ready to handle the challenges of today’s fast-paced digital landscape.
FAQs
When should I use CDC instead of batch loads?
When you need real-time data updates, low latency, and minimal disruption to your source systems, CDC (Change Data Capture) is the way to go. It’s perfect for streaming only the changes, ensuring dashboards or applications stay current without unnecessary delays. On the other hand, batch loads work better for infrequent, large-scale data transfers where immediate updates aren’t as important.
Should my primary keys be BIGINT or UUID v7?
When deciding between BIGINT and UUID v7, it boils down to your application's scalability and performance requirements.
UUID v7 stands out in distributed systems because of its time-ordered design. This structure minimizes index fragmentation and makes data inserts more efficient. On the other hand, BIGINT is a solid choice for single-node environments but can face challenges when scaling across multiple nodes.
For applications that demand modern scalability and need to avoid conflicts, UUID v7 tends to be the more practical option.
What’s the minimum setup to stop SQL injection?
To protect against SQL injection, the absolute minimum setup involves using query parameterization. This includes techniques like prepared statements with bound parameters. By doing so, you ensure that any user input is treated strictly as data, not as executable code. This approach effectively neutralizes SQL injection attempts and is a crucial first step in securing your database connections.


